
6 Jun
2024
6 Jun
'24
7:13 p.m.
Alex,
Thanks for the reference to that article. But the trends it discusses (from Dec 2023)
are based on the assumption that all reasoning is performed by LLM-based methods. It
assumes that any additional knowledge is somehow integrated with or added to data stored
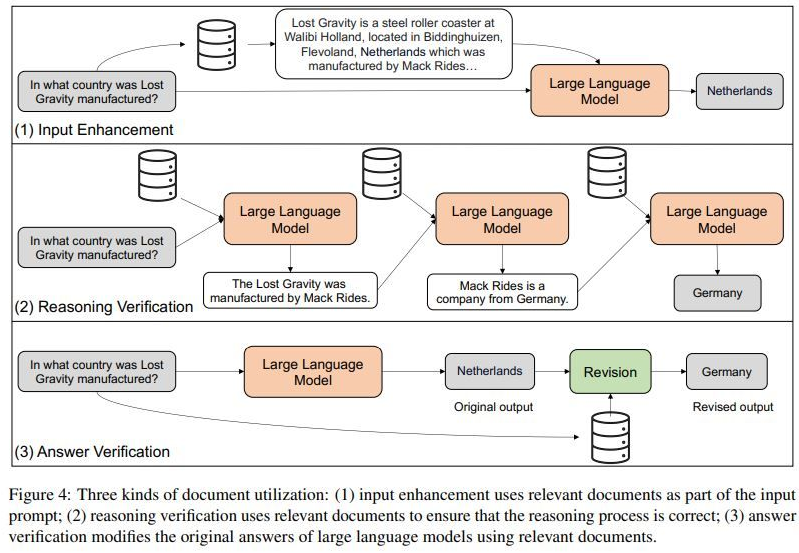
in LLMs. Figure 4 from that article illustrates the methods the authors discuss:
Note that the results they produce come from LLMs that have been modified by adding
something new. That article is interesting. But without an independent method of
testing and verification, Figure 4 is DIAMETRICALLY OPPOSED to the methods we have been
discussing and recommending in Ontolog Forum for the past 20 or more years.
The methods we have been discussing (which have been implemented and used by most
subscribers) are based on ontologies as a fundamental resource for supplementing, testing,
and reasoning with and about data from any source, including the WWW.
Most LLM-based methods, however, use untested data from the WWW. A large volume of that
data may be based on reliable documents. But an even larger volume is based on unreliable
or irrelevant data from untested, unreliable, erroneous, or deliberately deceptive and
malicious sources.
Even if the data sources are reliable, there is no guarantee that a mixture of reliable
data on different topics, when combined by LLMs, will be combined in a way that preserves
the accuracy of the original sources. Since LLMs do not preserve links to the original
sources, a random mixture of facts is not likely to remain factual.
In summary, the most reliable applications of LLMs are translations from one language
(natural or artificial) to another. Any other applications must be verified by testing
against ontologies, databases, and other reliable sources.
There are more issues to be discussed. LLMs are an important addition to the toolbox of
AI and computer science. But they are not a replacement for the precision of traditional
databases, knowledge bases, and methods of reasoning and computation.
John
______________________________________
From: "alex.shkotin" <alex.shkotin(a)gmail.com>
https://arxiv.org/abs/2311.05876 [Submitted on 10 Nov 2023 (v1), last revised 7 Dec 2023
(this version, v2)]
Large language models (LLMs) exhibit superior performance on various natural language
tasks, but they are susceptible to issues stemming from outdated data and domain-specific
limitations. In order to address these challenges, researchers have pursued two primary
strategies, knowledge editing and retrieval augmentation, to enhance LLMs by incorporating
external information from different aspects. Nevertheless, there is still a notable
absence of a comprehensive survey. In this paper, we propose a review to discuss the
trends in integration of knowledge and large language models, including taxonomy of
methods, benchmarks, and applications. In addition, we conduct an in-depth analysis of
different methods and point out potential research directions in the future. We hope this
survey offers the community quick access and a comprehensive overview of this research
area, with the intention of inspiring future research endeavors.
{kind=link}

7 Jun
7 Jun
10:36 a.m.
New subject: Trends in Integration of Knowledge and Large Language Models : A Survey and Taxonomy
John, Alex, ...
I haven't found a use myself for the new spawn of chatbots but
the following is typical of reports I read from those who do
attempt to use them for research and not just entertainment.
Peter Smith • Another Round with ChatGPT
• https://www.logicmatters.net/2024/06/02/another-round-with-chatgpt/
Cheers,
Jon
On 6/6/2024 3:13 PM, John F Sowa wrote:
Alex,
Thanks for the reference to that article. But the trends it discusses (from Dec 2023)
are based on the assumption that all reasoning is performed by LLM-based methods. It
assumes that any additional knowledge is somehow integrated with or added to data stored
in LLMs. Figure 4 from that article illustrates the methods the authors discuss:
Note that the results they produce come from LLMs that have been modified by adding
something new. That article is interesting. But without an independent method of
testing and verification, Figure 4 is DIAMETRICALLY OPPOSED to the methods we have been
discussing and recommending in Ontolog Forum for the past 20 or more years.
The methods we have been discussing (which have been implemented and used by most
subscribers) are based on ontologies as a fundamental resource for supplementing, testing,
and reasoning with and about data from any source, including the WWW.
Most LLM-based methods, however, use untested data from the WWW. A large volume of that
data may be based on reliable documents. But an even larger volume is based on unreliable
or irrelevant data from untested, unreliable, erroneous, or deliberately deceptive and
malicious sources.
Even if the data sources are reliable, there is no guarantee that a mixture of reliable
data on different topics, when combined by LLMs, will be combined in a way that preserves
the accuracy of the original sources. Since LLMs do not preserve links to the original
sources, a random mixture of facts is not likely to remain factual.
In summary, the most reliable applications of LLMs are translations from one language
(natural or artificial) to another. Any other applications must be verified by testing
against ontologies, databases, and other reliable sources.
There are more issues to be discussed. LLMs are an important addition to the toolbox of
AI and computer science. But they are not a replacement for the precision of traditional
databases, knowledge bases, and methods of reasoning and computation.
John
______________________________________
From: "alex.shkotin" <alex.shkotin(a)gmail.com>
https://arxiv.org/abs/2311.05876 [Submitted on 10 Nov 2023 (v1), last revised 7 Dec 2023
(this version, v2)]
Large language models (LLMs) exhibit superior performance on various natural language
tasks, but they are susceptible to issues stemming from outdated data and domain-specific
limitations. In order to address these challenges, researchers have pursued two primary
strategies, knowledge editing and retrieval augmentation, to enhance LLMs by incorporating
external information from different aspects. Nevertheless, there is still a notable
absence of a comprehensive survey. In this paper, we propose a review to discuss the
trends in integration of knowledge and large language models, including taxonomy of
methods, benchmarks, and applications. In addition, we conduct an in-depth analysis of
different methods and point out potential research directions in the future. We hope this
survey offers the community quick access and a comprehensive overview of this research
area, with the intention of inspiring future research endeavors.
12 Jun
12 Jun
2:56 a.m.
New subject: Trends in Integration of Knowledge and Large Language Models
Jon,
Thanks for that link. It shows why hopes that LLMs will magically lead to AGI (some kind
of intelligence that competes with or goes beyond the human level) are hopelessly
MISGUIDED. For passing a math test, they can get an A+ if they're lucky enough to
find the answers in their petabytes of random stuffing. But if they can't find a
correct solution, they're lucky to earn a C. Even worse, the LLMs are so stupid that
they can't say whether their results are good, bad, or indifferent.
The major strength of generatve AI technology is in providing an English-like (more
generally a natural-language like) interface to the AI reasoning technology of the past 60
years. That is extremely valuable, since the complex reasoning methods of GOFAI (Good
Old Fashioned AI) require years of studying to learn and use correctly.
But the hope that devoting billions of $$$ of computer horse power will produce AGI is
hopelessly misguided. A good state-of-the-art laptop with GOFAI and a modest amount of
LLM processing can outperform the biggest and most expensive LLM systems on the planet.
And it will do so with guaranteed accuracy. If it can't solve a problem, it will say
so. It won't produce garbage and claim that it's accurate.
Following Jon Awbrey's note is an excerpt that I extracted from the link that Jon
cited.
John
----------------------------------------
From: "Jon Awbrey" <jawbrey(a)att.net>
John, Alex, ...
I haven't found a use myself for the new spawn of chatbots but
the following is typical of reports I read from those who do
attempt to use them for research and not just entertainment.
Peter Smith • Another Round with ChatGPT
• https://www.logicmatters.net/2024/06/02/another-round-with-chatgpt/
Cheers,
Jon
_____________________________
Another round with ChatGPTBy Peter Smith / This and that / 4 Comments / June 2, 2024
ChatGPT is utterly unreliable when it comes to reproducing even very simple mathematical
proofs. It is like a weak C-grade student, producing scripts that look like proofs but
mostly are garbled or question-begging at crucial points. Or at least, that’s been my
experience when asking for (very elementary) category-theoretic proofs. Not at all
surprising, given what we know about its capabilities or lack of them.
But this did surprise me (though maybe it shouldn’t have done so: I’ve not really been
keeping up with discussions of the latest iteration of ChatGPT). I asked — and this was a
genuine question, hoping to save time on a literature search — where in the literature I
could find a proof of a certain simple result about pseudo-complements (and I wasn’t
trying to trick the system, I already knew one messy proof and wanted to know where else a
proof could be found, hopefully a nicer one). And this came back:
So I take a look. Every single reference is a total fantasy. None of the chapters/sections
have those titles or are about anything even in the right vicinity. They are complete
fabrications.
I complained to ChatGPT that it was wrong about Mac Lane and Moerdijk. It replied “I
apologize for the confusion earlier. Here are more accurate references to works that cover
the concept of complements and pseudo-complements in a topos, along with their proofs.”
And then it served up a complete new set of fantasies, including quite different
suggestions for the other two books.
[Following this example are two more paragraphs by Peter Smith and a few notes by other
readers who had similar experiences,]
311
days inactive
317
days old
2 comments
2 participants
participants (2)
-
 John F Sowa
John F Sowa -
 Jon Awbrey
Jon Awbrey