
23 May
2024
23 May
'24
5:06 a.m.
João,
Thanks for that reference. It's one more article that emphasizes the importance of
ontology and knowledge graphs (KGs) for detecting and correcting the errors and
hallucinations of LLMs. It's an example of the "Future directions" that
are necessary to make LLMs reliable.
By themselves, LLMs make two important contributions to AI: (1) They are very good for
translating natural languages and formal notations to other languages and notations. (2)
They are very good at generating hypotheses (guesses).
Unfortunately. LLMs cannot do reasoning. They can find and apply methods of reasoning,
but they are unable to do their own reasoning to evaluate the relevance and accuracy of
any results (guesses) that they generate.
The article by Allemang and Sequeda shows how to use KGs to evaluate and correct the
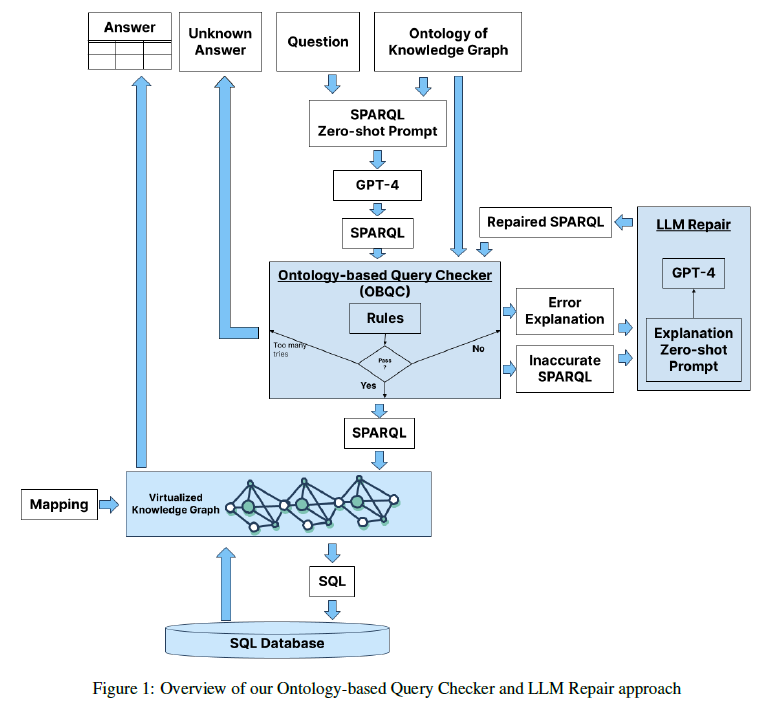
output from LLMs. Following is Figure 1 from their article:
This shows how they use GPT-4 to generate answers, which they check against an ontology.
If they detect errors, they go back to GPT-4 and repair the LLM output, which they
continue checking until the results are consistent with the ontology and an SQL database.
To represent information, they use a version of Knowledge Graphs (KGs) that can support
full first-order logic. Other notations for FOL could also be used. Peirce's
existential graphs have been extended to support conceptual graphs and the ISO standard
for Common Logic. They can support any reasoning by any version of KGs.
See below for the abstract and URL of the article. Note that their methods improved the
accuracy of LLMs from 16% to 54% by using KGs. With ontology, they obtained 18% more
correct answers and 8% "I don't k now." That leaves 20% wrong answers.
100% correct answers is probably unattainable, but the system should answer "I
don't know" for anything it does not know. Even without more data, more and
better ontology and reasoning should enable it to answer "I don't know" for
the remaining 20%.
John
_______________________________________
From: "João Oliveira Lima" <joaoli13(a)gmail.com>
Hi,
Yesterday the paper below was published on Arxiv, which may be of interest to this group.
Joao
Title: Increasing the LLM Accuracy for Question Answering: Ontologies to the Rescue!
Authors: Dean Allemang, Juan Sequeda
https://arxiv.org/pdf/2405.11706
Abstract: There is increasing evidence that question-answering (QA) systems with Large
Language Models (LLMs), which employ a knowledge graph/semantic representation of an
enterprise SQL database (i.e. Text-to-SPARQL), achieve higher accuracy compared to systems
that answer questions directly on SQL databases (i.e. Text-to-SQL). Our previous benchmark
research showed that by using a knowledge graph, the accuracy improved from 16% to 54%.
The question remains: how can we further improve the accuracy and reduce the error rate?
Building on the observations of our previous research where the inaccurate LLM-generated
SPARQL queries followed incorrect paths, we present an approach that consists of 1)
Ontology-based Query Check (OBQC): detects errors by leveraging the ontology of the
knowledge graph to check if the LLM-generated SPARQL query matches the semantic of
ontology and 2) LLM Repair: use the error explanations with an LLM to repair the SPARQL
query. Using the chat with the data benchmark, our primary finding is that our approach
increases the overall accuracy to 72% including an additional 8% of "I don't
know" unknown results. Thus, the overall error rate is 20%. These results provide
further evidence that investing knowledge graphs, namely the ontology, provides higher
accuracy for LLM powered question answering systems.
{kind=link}